32.Фильтры в excel.Виды фильтров.
Фильтрация данных позволяет отобразить в таблице только те строки, содержимое которых отвечает заданному условию. С помощью фильтров пользователь может в удобной для себя форме выводить или удалять (скрывать) записи списка.
В отличие от сортировки данные при фильтрации не переупорядочиваются, а лишь скрываются те записи, которые не отвечают заданным критериям выборки.
Отобранные записи можно форматировать и удалять, копировать в отдельную область таблицы, распечатывать, использовать для построения диаграмм и т.п.
Фильтрация данных может выполняться двумя способами: сиспользованием автофильтра и с использованием расширенного фильтра
ля поиска данных или записей в списках используются фильтры, которые отображают на экране только записи, соответствующие определенным условиям, а записи, не удовлетворяющие заданным требованиям, редактор временно скрывает. Отображенные записи (строки), можно форматировать, редактировать, распечатывать и т.д. К средствам фильтрации относятся:
Автофильтр (существуют два способа применения команды Автофильтр: с помощью меню «Данные» — «Фильтр» — «Автофильтр» — «раскрывающийся список команд автофильтра» и с помощью кнопки «Автофильтр» на панели инструментов стандартная)
Расширенный фильтр («Данные» — «Фильтр» — «Расширенный фильтр»)Автофильтр предназначен для простых условий отборов строк, а расширенный фильтр для более сложных условий отбора записей. Условие отбора — это ограничения, заданные для отбора записей, которые отбираются редактором для отображения на экране.
Работа с фильтрами и сортировкой
Для того чтобы отсортировать данные в ячейках выполните следующие действия:
1. Выберите диапазон, с которым вы хотите работать.
2. На вкладке Данные выберите Сортировка
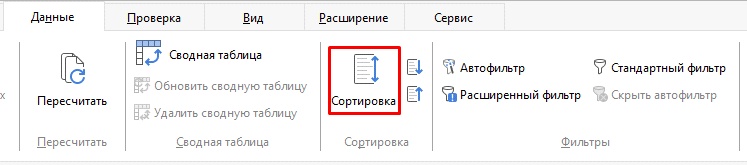
3. В окне Сортировка на вкладке Параметры настройте параметры сортировки.
Для мгновенной сортировки по возрастанию или по убыванию:
1. Выберите диапазон, с которым Вы хотите работать.
2. На вкладке Данные выберите Сортировка по возрастанию или Сортировка по убыванию.
В ACell есть три вида фильтров: стандартный фильтр, автофильтр и расширенный фильтр.
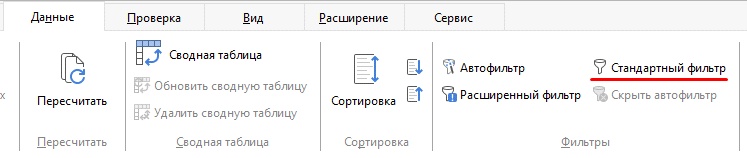
1. Выберите диапазон, с которым Вы хотите работать.
2. На вкладке Данные выберите Стандартный фильтр .
3. В окне Стандартный фильтр заполните имена полей данных, условие фильтрации и значение, по которому будет выполняться условие.
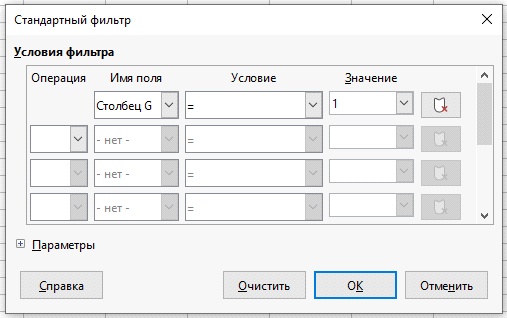
4. Нажмите ОК. В таблице отобразятся только отфильтрованные ячейки.
1. Выберите диапазон, с которым Вы хотите работать.
2. На вкладке Данные выберите Автофильтр .
3. Нажмите на значок треугольника рядом с названием столбца, чтобы настроить фильтрацию для данного столбца.
Например, с помощью Автофильтра можно произвести поиск данных по двум инструментам ( Цвет текста , Цвет фона )
Поиск данных по цвету фона:
1. Заполняем ячейки с значениями нужными нам цветами:
• Находим нужную нам ячейку, нажимаем на нее ЛКМ , переходим в раздел Шрифт , в данном разделе есть инструмент заливки Цвет фона .
• Нажимаем на него и выбираем палитру цветов для заполнения нужных нам ячеек.
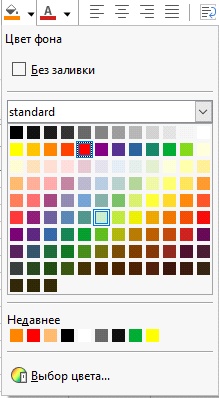
2. Находим значок автофильтра и нажимаем на него .
3. Переходим в тот столбец, в котором мы хотим произвести поиск значений.
4. В данном примере это будет столбец «A» , ячейка «Фамилия»
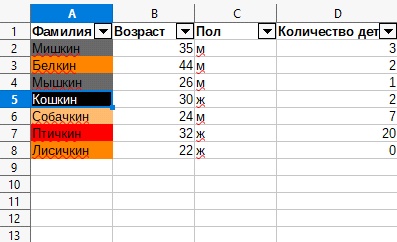
5. Нажимаем на флажок для открытия списка значений.
6. Нам откроется сортировочный список значений в данном столбце.
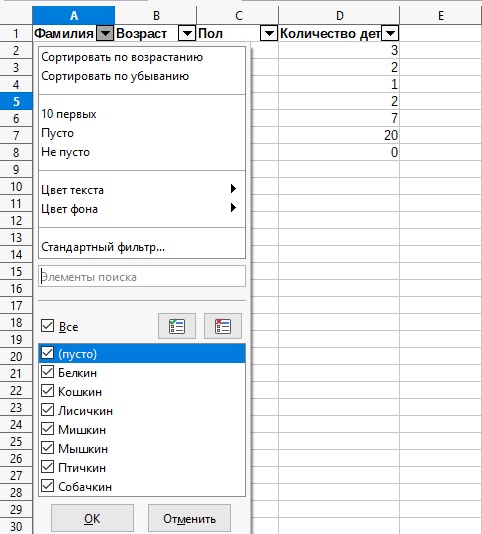
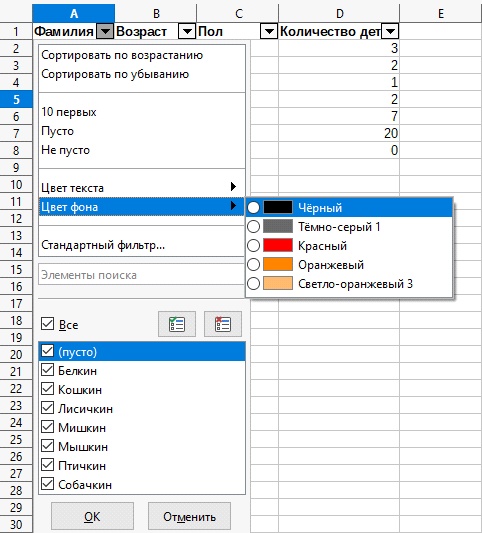
7. Находим раздел поиска «Цвет фона» , нажимаем на него.
8. Нам откроется дополнительное окошко с выбором цветов для поиска значений.
![]()
9. Выбираем нужный нам цвет для фильтра значений, в данном примере выступит
10. Нажимаем на него и как видим Автофильтр по «Цвету фона» сработал, он нашел нам нужное значение.
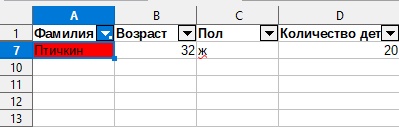
Поиск данных по цвету текста:
1. Заполняем значения нужным нам цветом:
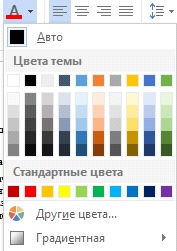
• Находим нужном нам значение, выделяем его с помощью ЛКМ , переходим в раздел Шрифт , в данном разделе есть инструмент Цвет текста .
• Нажимаем на него и выбираем палитру цветов для заполнения нужных нам значений.
2. Находим значок автофильтра и нажимаем на него .
3. Переходим в тот столбец, в котором мы хотим произвести поиск значений.
4. В данном примере это будет столбец «B» , ячейка «Возраст» .
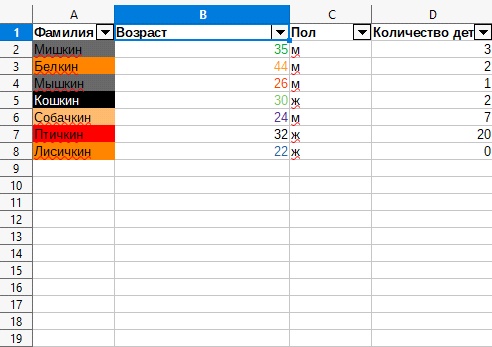
![]()
5. Нажимаем на флажок для открытия списка значений.
6. Нам откроется сортировочный список значений в данном столбце.
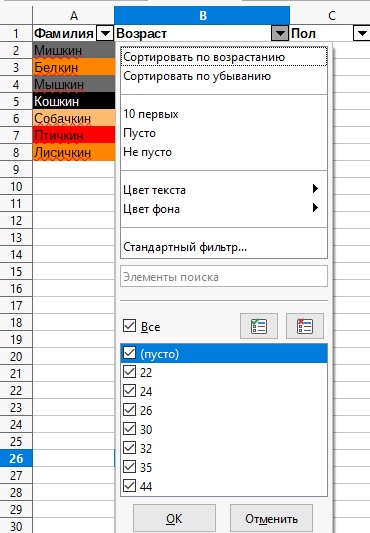
7. Находим раздел «Цвет текста» , нажимаем на него.
8. Нам откроется дополнительное окошко с выбором цветов для поиска значений.
![]()
9. Выбираем нужным нам цвет для фильтра значений, в данном примере выступит
10. Нажимаем на него и как мы видим Автофильтр по « Цвету текста» сработал, он нашел нам нужное значение.
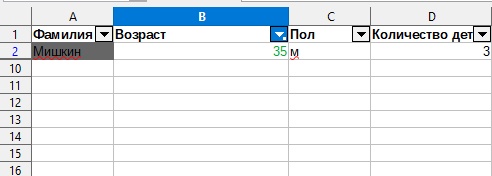
Расширенный фильтр — это фильтр, который позволяет использовать более 3 критериев фильтра. Чтобы использовать этот фильтр, Вам нужно создать массив, в который войдут критерии. Разберем использование расширенного фильтра на следующем примере.
Для создания массива:
1. Скопируйте строку с именами полей вашего диапазона (Имя, Возраст . ) в пустые ячейки на листе, например, в строку 10.
2. Введите критерии сортировки под нужными столбцами.
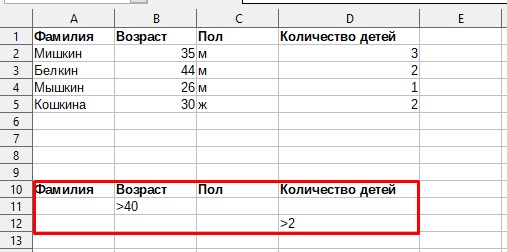
1. Выберите диапазон, с которым Вы хотите работать.
2. На вкладке Данные выберите Расширенный фильтр.
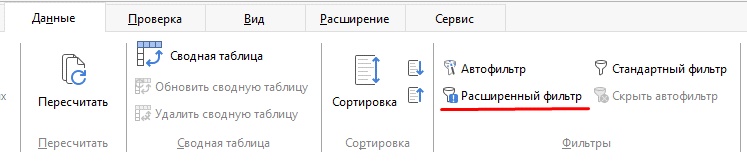
3. В появившемся окне выберите массив (строки 10-12) используя кнопку выбора.
4. В параметрах укажите, куда вы хотите поместить результат (строка 15).
Типы диаграмм
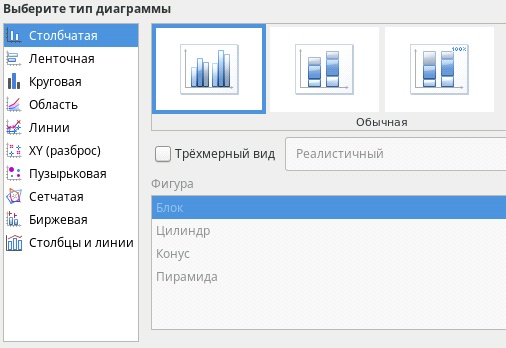
1. Столбчатая диаграмма , представленная прямоугольными зонами (столбцами), высоты или длины которых пропорциональны величинам, которые они отображают. Столбчатая диаграмма отображает сравнение нескольких дискретных категорий.
— обычная — одна ось показывает сравниваемые категории, другая — измеримую величину;
— с накоплением — показывает отношение отдельных составляющих к их совокупному значению, сравнивая по категориям вклад каждой величины в общую сумму;
— процентная с накоплением – тоже самое, что и с накоплением, но показывает процентное соотношение этих значений.
2. Ленточная диаграмма — это разновидность столбчатой диаграммы. Может также использоваться для иллюстрации плана, графика работ по какому-либо проекту (диаграмма Ганта).
— обычная – иллюстрирует сравнение отдельных элементов с возможностью группировки по категориям;
— с накоплением — показывает вклад отдельных величин в общую сумму;
— процентная с накоплением — тоже самое, что и с накоплением, но показывает процентное соотношение этих величин.
3. Круговая диаграмма — представляет данные в виде круга, разделенного на сектора. Каждый сектор — это категория данных, которая составляет долю от общей суммы.
— обычная – показывают вклад каждой величины в общую сумму в виде секторов, изображенных на целом круге;
— разделенная круговая – показывает вклад каждой величины в общую сумму, одновременно подчеркивая отдельные значения разделенными секторами;
— вложенная круговая — как и обычная круговая диаграмма отображает отношение частей к целому, но содержит более одного ряда данных для сравнения;
— разделенная вложенная круговая – тоже, что и вложенная круговая, но одновременно подчеркивает отдельные значения разделенными секторами.
4. Область — представляет собой линейную диаграмму, в которой область ниже линии заполнена индивидуальным цветом или текстурой, используется для отображения развития количественных значений в каком-то определенном интервале и позволяет оценить вклад каждого элемента в рассматриваемый процесс.
— обычная – иллюстрируют величину изменений в зависимости от времени, наглядно показывая вклад каждого ряда;
— с накоплением – показывают изменения вклада каждой величины с течением времени или по категориям;
— процентная с накоплением — показывают изменения вклада каждой величины в процентах с течением времени или по категориям.
5. Линии или графики — это графическое представление данных, которые изображаются в виде точек, соединённых линиями. Точки могут быть как видимыми, так и невидимыми. В основном, эти типы диаграмм используются для визуализации данных во времени.
— только точки – показывают непрерывное изменение данных с течением времени в едином масштабе, при этом значения отображаются только точками;
— линии и точки – в этом типе линейных диаграмм данные отображаются точками соединёнными линиями;
— только линии – в этом типе линейных диаграмм данные отображаются только соединёнными линиями без точек;
— трехмерные линии — на трехмерных графиках каждая строка или столбец изображаются в виде объемной ленты.
6. XY (разброс) — представляет собой точечную диаграмму в виде графика, получаемого путем нанесения в определенном масштабе экспериментальных точек, полученных в результате наблюдений. На таких диаграммах удобно демонстрировать связь между числовыми значениями, входящими в разные ряды данных; на диаграмме можно показать две группы чисел в виде одной последовательности точек.
— только точки – в этом подтипе данные выводятся только в виде точек, например, используются, когда соединительные линии могут затруднить восприятие или нет необходимости показывать связь между точками данных;
— линии и точки – на диаграмме этого типа точки данных соединяются прямыми линиями, при этом точки также отображаются;
— только линии – на диаграмме этого типа точки данных соединяются прямыми линиями, при этом точки не отображаются;
— трехмерные линии — на диаграмме этого типа каждый ряд данных отображается в виде объемной ленты.
7. Пузырьковая — это разновидность точечной диаграммы, в которой точки данных заменены пузырьками, причем их размер служит дополнительным измерением данных.
Это специфический тип диаграмм, способный отображать трехмерные данные в двумерном пространстве.
8. Сетчатая — это аналог линейной диаграммы, но в ней может быть несколько осей. По каждой из них производится отсчет от начала координат, находящегося в центре. Для каждого набора значений можно создать свою ось, исходящую из центра диаграммы. Внешне эта диаграмма напоминает сетку, или паутину – отсюда ее название.
— только точки – на диаграмме этого типа данные отображаются только точками на осях координат, исходящих из центра;
— линии и точки – на диаграмме этого типа данные отображаются точками соединенными линиями для каждого набора значений, на осях координат, исходящих из центра;
— только линии – на диаграмме этого типа данные отображаются только соединенными линиями для каждого набора значений, на осях координат, исходящих из центра;
— заливка – на диаграмме данного типа соединенные линии для каждого набора значений на осях координат, исходящих из центра, образуют области, которые заливаются индивидуальным цветом или текстурой.
9. Биржевая — это диаграмма, специально созданная для работы с финансовыми данными. В этом типе диаграмм значения сравниваются со значениями максимума и минимума, открытия и закрытия, используемыми для отображения биржевых данных, отображаются с помощью маркеров. Однако, эта диаграмма может использоваться также для вывода научных данных, например, для демонстрации колебаний дневных или годовых температур.
Можно выбрать следующие типы:
— Бары – тип диаграмм, который отображает изменения цены актива в виде интервальных гистограмм (отрезков, столбцов, баров);
— Японские свечи – самый популярный вид биржевых диаграмм, построение основано на четырех показателях: точках открытия и закрытия, максимальной и минимальной цене за определенный промежуток времени;
— Бары с объемом – тоже что и тип – Бары, но для построения диаграммы и отображения добавляется ещё один параметр – объемы продаж;
— Японские свечи с объемом — тоже что и тип – Японские свечи, но для построения диаграммы и отображения добавляется ещё один параметр – объемы продаж;
10. Столбцы и линии – это тип диаграмм, в которых одновременно совмещаются столбчатые и линейные диаграммы.
Можно выбрать следующие подтипы:
— Столбцы и линии – представляет собой комбинацию столбчатой и линейчатой диаграммы. Прямоугольники ряда данных столбца отображаются рядом, что упрощает сравнение их значений.
— Столбцы и линии с накоплением — представляет собой комбинацию столбчатой и линейчатой диаграммы, при этом прямоугольники ряда данных в столбце отображаются один над другим так, что высота столбца представляет собой сумму значений данных.
Виды фильтров в acell
Фильтр — это быстрый и легкий способ поиска подмножества данных и работы с ними в списке. В отфильтрованном списке отображаются только строки, отвечающие условиям. В отличие от сортировки, фильтр не меняет порядок записей в списке. При фильтрации временно скрываются строки, которые не требуется отображать.
Строки, отобранные при фильтрации, можно редактировать, форматировать, создавать на их основе диаграммы, выводить их на печать, не изменяя порядок строк и не перемещая их.
При фильтрации выбираются только необходимые данные, а остальные данные скрываются. Таким образом, отображается только то, что вы хотите увидеть, и это можно сделать одним щелчком.
При фильтрации данные никак не изменяются. Как только фильтр удален, все данные появляются снова в том же виде, в каком они были до применения фильтра.
В Excel доступны две команды для фильтрации списков:
- Автофильтр, включая фильтр по выделенному, для простых условий отбора.
- Расширенный фильтр для более сложных условий отбора.
Автофильтр
Для включения Автофильтра нужно выделить любую ячейку в таблице, затем на вкладке Данные в группе Сортировка и фильтр нажать большую кнопку Фильтр:
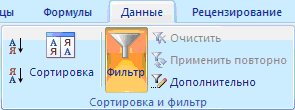
После этого в шапке таблицы справа от каждого заголовка столбца появится кнопка со стрелкой вниз :

Щелчок по стрелке открывает меню со списком для соответствующего столбца. В списке содержатся все элементы столбца в алфавитном или числовом порядке (в зависимости от типа данных), так что можно быстро найти требуемый элемент:
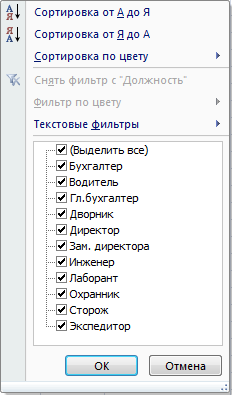
Если нам нужен фильтр только для одного столбца, то можно не выводить кнопки со стрелкой для остальных столбцов. Для этого перед нажатием кнопки Фильтр выделяем несколько ячеек нужного столбца вместе с заголовком.
Фильтрация по точному значению
Включаем Автофильтр, щелкаем по кнопке со стрелкой и выбираем из раскрывшегося списка какое-нибудь значение. Для того, чтобы быстро выделить все элементы столбца или снять выделение со всех элементов, щелкните по пункту (Выделить все):
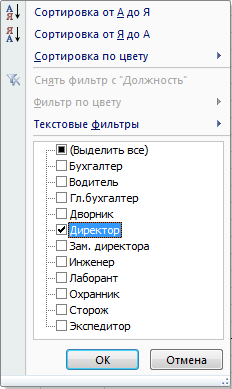
При этом все строки, в поле которых не содержится выбранное значение, скрываются.
При выполнении лабораторной работы, выделяем результат фильтрации, копируем на другое место листа и подписываем.
Для выключения Автофильтра нужно еще раз нажать кнопку Фильтр.
Для отмены действия фильтра, не выходя из режима фильтрации, щелкаем по кнопке и выбираем из раскрывшегося списка пункт (Выделить все). При этом появляются скрытые фильтром строки таблицы.
Признаки фильтрации данных
Фильтры скрывают данные. Именно для этого они и предназначены. Однако, если о фильтрации данных не известно, может возникнуть впечатление, что некоторые данные пропущены. Вы могли, например, открыть чей-нибудь отфильтрованный лист или даже забыть, что сами ранее применили фильтр. Поэтому когда на листе есть фильтры, можно обнаружить различные визуальные указатели и сообщения.
Строка состояния (находится слева внизу окна). Исходное состояние:
Сразу после фильтрации данных итог применения фильтра отображаются в левом нижнем углу строки состояния. Например, “Найдено записей: 2 из 11”:

Номера строк. По прерывистым номерам строк можно сказать, что некоторые строки скрыты, а изменившийся цвет номеров видимых строк указывает на то, что выделенные строки являются результатом отбора фильтра.
Вид стрелок. Изменение стрелки автофильтра в отфильтрованном столбце на указывает на то, что данный столбец отфильтрован.
Фильтр “Первые 10…”
“Первые 10…” — это еще один универсальный фильтр, который можно применять к столбцам с числами или датами.
“Первые 10…” — это очень условное название. На самом деле возможности этого фильтра гораздо шире. С помощью этого фильтра можно находить или первые элементы или последние элементы (наименьшие или наибольшие числа либо даты). И, вопреки названию фильтра, получаемые результаты не ограничиваются первыми 10 элементами или последними 10 элементами. Число отображаемых элементов можно выбирать от 1 до 500.
Фильтр “Первые 10…” позволяет также отбирать данные по проценту от общего числа строк в столбце. Если в столбце содержится 100 чисел и требуется просмотреть наибольшие пятнадцать, то выбираем 15 процентов.
Фильтр можно использовать для нахождения продуктов с наибольшими или наименьшими ценами, для определения списка сотрудников, нанятых последними по времени, или для просмотра списка студентов с наилучшими или наихудшими отметками. Чтобы применить фильтр “Первые 10…” к столбцу данных (только числа или даты . ), щелкаем в столбце стрелку и выбираем пункт Числовые фильтры далее Первые 10…:
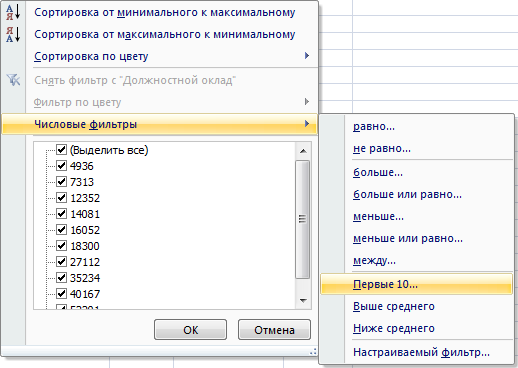
После этого откроется диалоговое окно Наложение условия по списку:
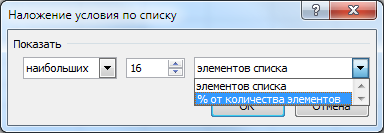
В диалоговом окне выбираем число (строк или процентов), наибольших или наименьших, элементов списка или % от количества элементов.
Создание собственных настраиваемых фильтров
Фильтр по шаблону
Например, нам нужно вывести только строки с должностями, начинающимися с буквы ‘Д’. Для этого щелкаем по стрелке автофильтра в первом столбце и выбираем Текстовые фильтры, затем пункт начинается с…:
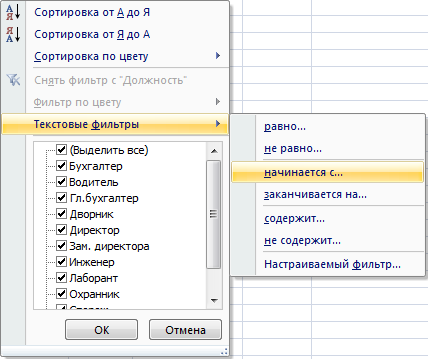
При этом появится диалоговое окно Пользовательский автофильтр (какой бы пункт справа вы бы ни выбирали, все равно появится одно и то же диалоговое окно.):
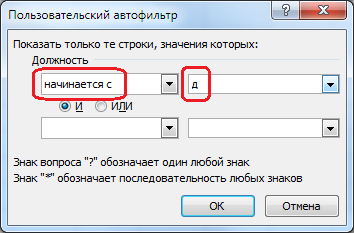
В поле Должность выбираем – начинается с, справа вводим д:
В окне Пользовательский автофильтр есть подсказка:
Знак вопроса “?” обозначает один любой знак.
Знак “*” обозначает последовательность любых знаков.
Поэтому, для того чтобы найти все строки содержащие значение (например, имя) начинающееся с Ан и содержащее 5 букв, зададим шаблон Ан. . Если же количество букв может быть любое, то зададим шаблон Ан*. Значение регистра в шаблоне не имеет значения.
Точно также можно наоборот выбрать строки, в которых отсутствуют данные, подходящие под шаблон. Для этого, например, в диалоговом окне Пользовательский автофильтр выбираем в поле Должность – не равно:
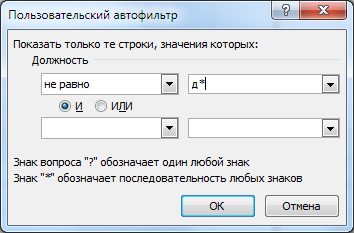
Для удобства работы с пользовательскими шаблонами можно использовать другие условия:
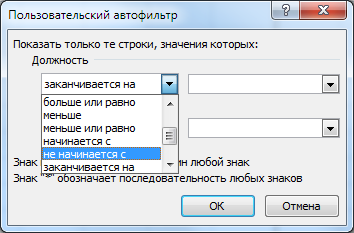
Фильтрация по диапазону значений
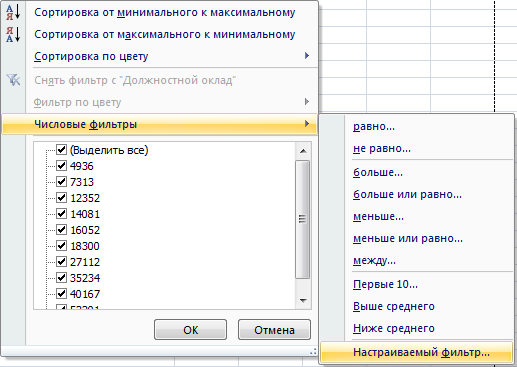
Например, нам нужно вывести список должностей с окладами в диапазоне от 10000 рублей до 18000 рублей (“середнячки”).
Для этого щелкаем по стрелке автофильтра в третьем столбце и далее Числовые фильтры → Настраиваемый фильтр:
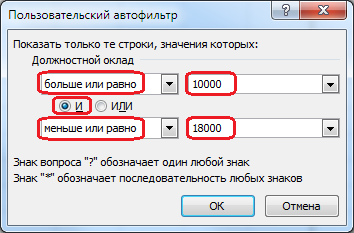
При этом появится то же самое диалоговое окно Пользовательский автофильтр. В поле Должностной оклад выбираем – больше или равно, справа набираем 10000, ниже выбираем логическую операцию – И, еще ниже слева – меньше или равно, справа внизу – 18000:
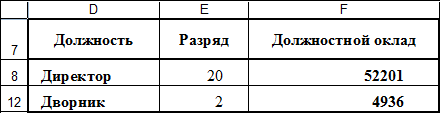
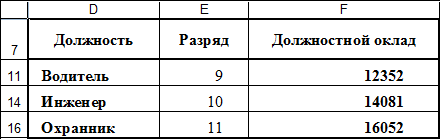
Результат фильтрации:
Для выбора должностей с окладами, не попадающими в диапазон от 10000 рублей до 18000 рублей (“самые бедные” и “самые богатые”), используем логическую операцию “ИЛИ”: